I have a lot more time to think about coding issues than I have time to code. In some ways, this is quite handy as it allows me to plan through certain problems and foresee potential pitfalls of a particular solution. I think there are two key problems with this, however. First, even if I come up with a solution it's still only half the job done. Second, it gets be bogged down in coding problems that often are beyond my coding abilities.
This all became apparent in the last month when I became bogged down in a particular design problem. A month later, I'm still no closer to a solution, and worse still I'm not making any progress in any other area. And instead of just coding a workaround for the time being, I became fixated on solving the problem.
(I needed compile-time polymorphism where I previously had run-time polymorphism. I read through books and websites on templating, tried rudimentary attempts at adjusting my code, but always I was trying to code up a perfect solution in my head, weighing up potential considerations and pitfalls. And at the end of it, all I have is the lament I just didn't code around it.)
What I find so disappointing is I know all this. There's nothing particularly revelatory in that I dwell on problems instead of working around them, but it is disappointing that I still haven't moved on from the problems I had when I was at university learning to code. I get too hung up on solutions that I haven't learnt how to code around it.
This game coding happens in the limited spare time I have. It's a hobby, and comes after other aspects of work and life. So maintaining motivation is always a struggle, especially in the face of seeming blockers. And from what I've come to know about the role pressure plays in inhibiting the creative process, the limited time often translates into fixating on particular solutions instead of just getting on with something else.
Given that I'm still adjusting back into C++, it's easy for me to think of failures as a lack of knowledge of the language itself. Sometimes that's apparent, and I know as I'm reading through various C++ material that I'm skimming for a particular solution context rather than internalising the language feature as a potential design tool in the future. But I think it would be a cop-out to blame my current understanding of C++ when the language is so flexible in the kinds of solutions that are permitted.
It's always, I think, going to be a question of motivation. That is, am I able to code something that's good enough for the task at hand? One thing that's problematic is that my initial scope is far too ambitious – that is, I'm trying to create a framework that could be used to make any number of 2D games. So in that respect I'm stuck trying to figure out generic solutions.
And therein lies the problem. How do I know I'm going to get to use any of the design work I've put in so far? For example, all the time I spent writing wrapper objects for SDL code, as far as I can tell, has had very little benefit so far. Indeed, the main reason I did that was to have a sort of platform agnosticism – the theory was that I could refactor out the core features of the engine to a different library without having to permeate those decisions down through game code. Yet if I'm never going to do that, then as happy as I am with some of the wrapper code I wrote, then a lot of that effort was wasted.
(Funnily enough, as I was trying to learn SDL, one thing I got frustrated with was that the tutorials were so direct in their use of the libraries. I took it as an act of clarity on account of the tutorial writers that they didn't try to muddle things up by enclosing their code in some simple patterns. But as I was coding up my input system, I wondered just what benefit I was getting out of mapping SDL structures with my own.)
This too, I think, highlights the perils of solo development. As I'm working on this project, I'm accountable to one person: myself. What I design, what I build, what my desired end-product is – all that is my decision. And since I'm starting from scratch and working completely unguided, it’s inevitable that I'm going to not only make bad decisions, but those bad decisions will lead t o a lot of wasted time. You live, you (hopefully) learn.
What I think I've learnt is something about the limitations of myself. If I have a certain disposition to coding a certain way, then it would be madness to think I can just overcome it by saying "don't". What I hoped with prototype-driven design was that I could better focus on what needs to be done, rather than what I would think might need to be done. That, now, seems like only addressing half of the equation, and what's missing are techniques for build-and-refactor so I don’t get bogged down where an elegant solution is not immediately apparent.
I know at times I need to get out of my head – I have notebooks that are filling up with ideas faster than I'm adding lines of code to the codebase. What will remain to be seen is if I can work with my own personal practices and habits. Like losing weight, if you try to do it on willpower, then you’re going to fail miserably.
Showing posts with label programming. Show all posts
Showing posts with label programming. Show all posts
Monday, 15 December 2014
Sunday, 23 November 2014
The How of A*
(For the Why of A*, go here)
Here is a basic implementation of A*. Note that this isn’t necessarily an optimal solution, but it is a working one.
For my solution, I have two classes: Node and PathfindingAStar. The two classes are tightly coupled, with Pathfinding depending on Node to have certain properties in order to work. Node itself is the bridge between the pathfinding subsystem and the wider system.
Here is Node.h:
Secondly, the node holds information relevant to the cycle of the path. m_g and m_h are used by Pathfinding for the node’s distance from the start node and to the goal node. Similarly, m_parent is used to keep track of where the navigation came from.
As far as methods in Node.cpp go, there are two methods that are worth exploring, both to do with the available directions.
Since directions are set when neighbours are set, there’s never any need to worry about the two maps going out of sync. So either map could have been iterated over to build a list for Pathfinding to use. This returned list could just as easily have been a private member of Node, generated as part of the setting of neighbours, and perhaps could be a point of efficiency to do so in the future.
Here is the source code for PathfindingAStar.h:
The main algorithm is a while loop, which will run until either the goal Node is found, or the frontier list is exhausted. The Node at the front of the frontier list (sorted by f) is checked for whether it is in-fact the goal Node, in which case the algorithm constructs the list of Nodes and returns it. Otherwise, the Node goes through each available direction on the current Node, removes it from the frontier list, and adds it to the closed list.
For each neighbour Node, it needs to be checked whether it’s already a) on the frontier, or b) on the closed list. In either of these cases, the Node needs no further exploration except in one special case of a Node on the frontier. If the distance travelled to the Node in this iteration is less than the distance travelled to the Node, then the Node and frontier list need to be updated. i.e. we have found a shorter path to the same position. If the neighbour Node is not yet explored, its g and h are calculated (in this case, h is calculated using the Manhattan heuristic), its parent is set as the current Node, then it is put onto the frontier list sorted by f. Finally, if the frontier list is exhausted, this means there was no path from the start Node to the goal Node, so an empty list is created and returned. Thus the empty() function on list acts as the indicator of whether there was path successfully generated.
The code for building the path list is as follows:
And there it is – a basic implementation of the A* algorithm. It’s by no means the most efficient possible version of the algorithm, nor does it do any of the C++ things one really ought to do when using the language. The important thing is that it works, and it’s reasonably clear how.
Here is a basic implementation of A*. Note that this isn’t necessarily an optimal solution, but it is a working one.
For my solution, I have two classes: Node and PathfindingAStar. The two classes are tightly coupled, with Pathfinding depending on Node to have certain properties in order to work. Node itself is the bridge between the pathfinding subsystem and the wider system.
Here is Node.h:
typedef struct
{
unsigned int x;
unsigned int y;
}NodePos;
class Node
{
public:
Node(unsigned int p_x, unsigned int p_y);
~Node();
NodePos getPosition();
bool isSameNode(Node* p_node);
void setNeighbourAt(Direction p_dir, Node* p_neighbour, double p_cost = 1.0);
Node* getNeighbourAt(Direction p_dir);
unsigned int getMovementCost(Direction p_dir);
std::vector getAllAvailableDirections();
bool isOccupied();
void setOccupied(bool p_occupied);
void setParent(Node* p_parent);
Node* getParent();
double getG();
void setG(double p_distanceTravelled);
double getH();
void setH(double p_heuristic);
double getF();
unsigned int getX();
unsigned int getY();
private:
std::map m_movementCost;
NodePos m_pos;
std::map m_neighbours;
Node *m_parent;
bool m_occupied;
double m_h;
double m_g;
};
Secondly, the node holds information relevant to the cycle of the path. m_g and m_h are used by Pathfinding for the node’s distance from the start node and to the goal node. Similarly, m_parent is used to keep track of where the navigation came from.
As far as methods in Node.cpp go, there are two methods that are worth exploring, both to do with the available directions.
void Node::setNeighbourAt(Direction p_dir, Node* p_neighbour, double p_cost)
{
m_neighbours[p_dir] = p_neighbour;
m_movementCost[p_dir] = p_cost;
}
std::vector Node::getAllAvailableDirections()
{
std::vector directions;
directions.clear();
std::map::iterator itr;
std::pair pair;
for(itr = m_movementCost.begin(); itr != m_movementCost.end(); itr++)
{
pair = *itr;
directions.push_back(pair.first);
}
return directions;
}
Since directions are set when neighbours are set, there’s never any need to worry about the two maps going out of sync. So either map could have been iterated over to build a list for Pathfinding to use. This returned list could just as easily have been a private member of Node, generated as part of the setting of neighbours, and perhaps could be a point of efficiency to do so in the future.
Here is the source code for PathfindingAStar.h:
#include "Node.h"
class PathfindingAStar
{
public:
static PathfindingAStar* getInstance();
~PathfindingAStar();
std::list findPath(Node* p_startNode, Node* p_goalNode);
private:
std::list finalisePath(Node* p_currentNode);
PathfindingAStar();
static PathfindingAStar *singleton;
};
std::list PathfindingAStar::findPath(Node* p_startNode, Node* p_goalNode)
{
std::vector m_openList; //Nodes that are active
std::vector m_closedList; //Nodes that have been used
//Clear the list
m_openList.clear();
m_closedList.clear();
//Reset the node to parent for the current cycle
p_startNode->setParent(0);
//and reset all values of f, g & h
p_startNode->setG(0.0);
double h = (double) abs(p_goalNode->getX() - p_startNode->getX());
h += (double) abs(p_goalNode->getY() - p_startNode->getY());
p_startNode->setH(h);
m_openList.push_back(p_startNode);
while (!m_openList.empty()) //If there are still nodes to explore
{
//Get the node with the smallest f value
Node* currentNode = m_openList.front();
//Remove node from the open list
std::vector::iterator itr = m_openList.begin();
m_openList.erase(itr);
if (currentNode->isSameNode(p_goalNode))
{
std::list goalList = finalisePath(currentNode);
//return out of the program
return goalList;
}
std::vector neighbours = currentNode->getAllAvailableDirections();
bool isFound;
for (unsigned int i = 0; i < neighbours.size(); i++) {
isFound = false;
Node *n = currentNode->getNeighbourAt(neighbours[i]);
if (n->isOccupied()) {
continue;
}
//Make sure node isn't in open list
for (unsigned int j = 0; j < m_openList.size(); j++) {
Node *n2 = m_openList.at(j);
if (n2 == n)
{
double g = currentNode->getG() + currentNode->getMovementCost(neighbours[i]);
if (g < n2->getG())
{
std::vector::iterator itr2 = m_openList.begin();
m_openList.erase(itr2 + j);
for (; itr2 != m_openList.end(); itr2++)
{
Node* n2 = *itr2;
if (n->getF() <= n2->getF())
{
break;
}
}
m_openList.insert(itr2, n);
n2->setG(g);
n2->setParent(currentNode);
}
isFound = true;
break;
}
}
if (isFound)
continue;
for (unsigned int j = 0; j < m_closedList.size(); j++)
{
Node *n2 = m_closedList.at(j);
if (n2 == n)
{
isFound = true;
break;
}
}
if (isFound)
continue;
n->setParent(currentNode);
//work out g
n->setG(currentNode->getG() + currentNode->getMovementCost(neighbours[i]));
//work out h
h = (double) abs(p_goalNode->getX() - n->getX());
h += (double) abs(p_goalNode->getY() - n->getY());
n->setH(h);
//add to open list in order
std::vector::iterator itr2 = m_openList.begin();
for (; itr2 != m_openList.end(); itr2++)
{
Node* n2 = *itr2;
if (n->getF() <= n2->getF())
{
break;
}
}
m_openList.insert(itr2, n);
}
m_closedList.push_back(currentNode);
}
std::list dummylist;
return dummylist;
}
The main algorithm is a while loop, which will run until either the goal Node is found, or the frontier list is exhausted. The Node at the front of the frontier list (sorted by f) is checked for whether it is in-fact the goal Node, in which case the algorithm constructs the list of Nodes and returns it. Otherwise, the Node goes through each available direction on the current Node, removes it from the frontier list, and adds it to the closed list.
For each neighbour Node, it needs to be checked whether it’s already a) on the frontier, or b) on the closed list. In either of these cases, the Node needs no further exploration except in one special case of a Node on the frontier. If the distance travelled to the Node in this iteration is less than the distance travelled to the Node, then the Node and frontier list need to be updated. i.e. we have found a shorter path to the same position. If the neighbour Node is not yet explored, its g and h are calculated (in this case, h is calculated using the Manhattan heuristic), its parent is set as the current Node, then it is put onto the frontier list sorted by f. Finally, if the frontier list is exhausted, this means there was no path from the start Node to the goal Node, so an empty list is created and returned. Thus the empty() function on list acts as the indicator of whether there was path successfully generated.
The code for building the path list is as follows:
std::list PathfindingAStar::finalisePath(Node* p_currentNode)
{
std::list goalList;
while (p_currentNode != NULL)
{
goalList.push_front(p_currentNode);
p_currentNode = p_currentNode->getParent();
}
//don't need the first node
goalList.pop_front();
return goalList;
}
And there it is – a basic implementation of the A* algorithm. It’s by no means the most efficient possible version of the algorithm, nor does it do any of the C++ things one really ought to do when using the language. The important thing is that it works, and it’s reasonably clear how.
Saturday, 22 November 2014
The Why of A*
For pathfinding, breadth-first search (BFS) is almost always preferable to depth-first search (DFS). The general problem of a breadth-first search is that it is resource-intensive. Depth-first follows a single path that grows as the path is explored. Breadth-first explores multiple paths at once, with the amount of paths growing exponentially.


Both DFS and BFS are brute force attempts at finding a path, but they express themselves in different ways. A depth-first will in all likelihood find a path that won’t directly go from A to B, but follow the rules which govern how to choose the next position to explore. A breadth-first search might find a more direct path from A to B, but the result will take much more time to compute – something that’s unforgivable in a game which requires immediate feedback.
There are ways of directing a BFS so that it doesn’t take as much computational power. A* is the best of these, but it’s worth at least glancing over why this is the case. A* works on the following equation:
One strategy with a BFS is to just take into account the shortest distance to the goal. So whatever node is “closest” (and there are various strategies for working this out) should be the next node to search. This strategy works well if there are no obstacles directly between the start node and the goal node, as the closest node will always bring the path closer to the goal. The strategy fails, however, if there are obstacles, because the path will inevitably explore those dead ends like a DFS would.

A* gets around this problem by also taking into account just how far the path has travelled. In other words, what makes a path the most fruitful to explore is the estimated total of the journey. A path that goes down a dead end will have an overall larger journey than a path that took a deviation before the dead end path.

With the A* algorithm, the final output would be a path that always has the least number of moves between A and B calculated with exploring as little of the search tree as necessary. The algorithm, like with any algorithm, has its limitations, but ought to be used where the start and end goals are known and need to be computed.
Both DFS and BFS are brute force attempts at finding a path, but they express themselves in different ways. A depth-first will in all likelihood find a path that won’t directly go from A to B, but follow the rules which govern how to choose the next position to explore. A breadth-first search might find a more direct path from A to B, but the result will take much more time to compute – something that’s unforgivable in a game which requires immediate feedback.
There are ways of directing a BFS so that it doesn’t take as much computational power. A* is the best of these, but it’s worth at least glancing over why this is the case. A* works on the following equation:
f = g + hWhere g is the total distance travelled, h is the estimated distance left to travel, and the smallest f is chosen next. An undirected BFS would be the equivalent of ignoring h altogether, so it’s worth exploring the role of h.
One strategy with a BFS is to just take into account the shortest distance to the goal. So whatever node is “closest” (and there are various strategies for working this out) should be the next node to search. This strategy works well if there are no obstacles directly between the start node and the goal node, as the closest node will always bring the path closer to the goal. The strategy fails, however, if there are obstacles, because the path will inevitably explore those dead ends like a DFS would.
A* gets around this problem by also taking into account just how far the path has travelled. In other words, what makes a path the most fruitful to explore is the estimated total of the journey. A path that goes down a dead end will have an overall larger journey than a path that took a deviation before the dead end path.
With the A* algorithm, the final output would be a path that always has the least number of moves between A and B calculated with exploring as little of the search tree as necessary. The algorithm, like with any algorithm, has its limitations, but ought to be used where the start and end goals are known and need to be computed.
Monday, 3 November 2014
Phase 3b: Flip Squares
With Snake, I could contain the notion of a Level within the screen itself, starting at (0,0) for both the top left coordinate and the offset for rendering the game objects. Going forward, this was not sustainable. Furthermore, I had no way of capturing or processing mouse input on the screen – limiting the engine in effect to whatever could be done solely with keyboard. Finally, there was no way of putting text onto the screen.
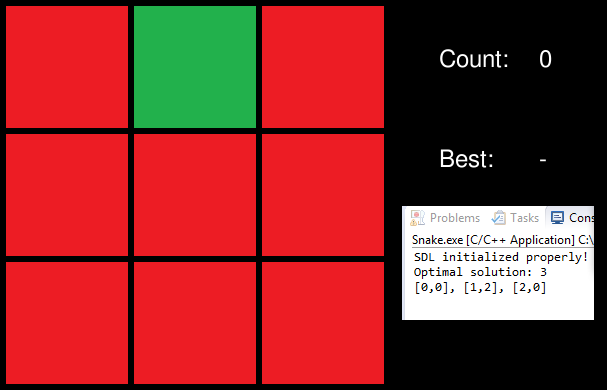
Since Snake wasn't really suited to these tasks, I decided to make a new prototype. I remembered an old puzzle from Black & White whereby you had to make a set of randomised trees all the same type. The rule was fairly simple – you had a 3x3 set of trees. If you pulled on a tree, it changed the tree and changed every neighbour of the tree. So there were patterns of 3, 4, or 5 changing depending on the location. Simple enough to code such that the game code itself wouldn't take up much of the development, yet would be useful to get all three aspects missing from the system coded up.
The Camera was a crucial class to get right, and if I was being honest, working out the logic for it has been something that I've been trying to get right in my head for months. Indeed, it was the bane of phase 1 and phase 2. With Level finally sorted out, it was more a matter of getting Camera right. The Level introduced the idea of WorldCoordinate – a simple structure that holds two doubles. So Camera could have a position relative to the Level by holding a world coordinate and the tile dimensions.
Camera needed to do a number of other things. For one, Camera had to be accessible by every AnimationObject so that the destination rect could be relative to the Camera rather than the level. This way textures could be updated out of sight of the game code. The other major thing was to keep track of the mouse, to keep track of where it is on screen and to be able to translate back into a WorldCoordinate for use in-game.
When designing my Input class in the abstract, I thought all I would need to do was keep track of the relative movement of the mouse. This proved to have a limited utility when running in Windowed mode – with the absolute position of the cursor sometimes moving out of the window altogether while not being able to reach certain objects in game. It’s this kind of phenomenon that has helped me understand how important prototypes are to getting the engine running right.
In order to get the prototype up and running, I avoided working out how to display a cursor, and instead used an overlay object for the squares themselves. It worked well enough, and well enough to force me to revisit the equations in the Camera class for getting the translation of WorldCoordinate right. By this stage, I had a working prototype, as seen here.
The last thing I wanted to do was to get text rendering on the screen. For the prototype, I wanted to display something simple – the number of moves in trying to solve the puzzle. With TextureObject (my wrapper of SDL_Texture), the textures were meant to live for the lifetime of the application, so it could be managed by TextureManager. With text, its creation and destruction needed to be with regards to its use. Obviously I don’t want this to be manual, so when I created TextObject (the text equivalent of AnimationObject) I handled the deletion of text objects in code.
It turned out getting text on screen was mostly straightforward. The only problem was the difference between relative and absolute positioning of text. Obviously I would want the option of having both, but I haven’t come up with a good solution yet. For now I’ve created two objects: TextObject and TextGameObject with game objects being camera-relative while TextObject has an absolute position. When I get to working on the HUD, I might encounter this problem with AnimationObject, so there’s a refactor issue.
In the absence of another prototype idea, I refactored the game itself with an algorithm to brute-force a solution. Taking a purely random approach to the game meant that occasionally really easy puzzles would be thrown up (I coded to stop 0-step puzzles). So I wrote an algorithm that would brute-force a solution - to work out just what are the moves needed to solve the puzzle from any given position. This didn't advance the engine in any way, but was a good coding exercise nonetheless.
Since Snake wasn't really suited to these tasks, I decided to make a new prototype. I remembered an old puzzle from Black & White whereby you had to make a set of randomised trees all the same type. The rule was fairly simple – you had a 3x3 set of trees. If you pulled on a tree, it changed the tree and changed every neighbour of the tree. So there were patterns of 3, 4, or 5 changing depending on the location. Simple enough to code such that the game code itself wouldn't take up much of the development, yet would be useful to get all three aspects missing from the system coded up.
The Camera was a crucial class to get right, and if I was being honest, working out the logic for it has been something that I've been trying to get right in my head for months. Indeed, it was the bane of phase 1 and phase 2. With Level finally sorted out, it was more a matter of getting Camera right. The Level introduced the idea of WorldCoordinate – a simple structure that holds two doubles. So Camera could have a position relative to the Level by holding a world coordinate and the tile dimensions.
Camera needed to do a number of other things. For one, Camera had to be accessible by every AnimationObject so that the destination rect could be relative to the Camera rather than the level. This way textures could be updated out of sight of the game code. The other major thing was to keep track of the mouse, to keep track of where it is on screen and to be able to translate back into a WorldCoordinate for use in-game.
When designing my Input class in the abstract, I thought all I would need to do was keep track of the relative movement of the mouse. This proved to have a limited utility when running in Windowed mode – with the absolute position of the cursor sometimes moving out of the window altogether while not being able to reach certain objects in game. It’s this kind of phenomenon that has helped me understand how important prototypes are to getting the engine running right.
In order to get the prototype up and running, I avoided working out how to display a cursor, and instead used an overlay object for the squares themselves. It worked well enough, and well enough to force me to revisit the equations in the Camera class for getting the translation of WorldCoordinate right. By this stage, I had a working prototype, as seen here.
The last thing I wanted to do was to get text rendering on the screen. For the prototype, I wanted to display something simple – the number of moves in trying to solve the puzzle. With TextureObject (my wrapper of SDL_Texture), the textures were meant to live for the lifetime of the application, so it could be managed by TextureManager. With text, its creation and destruction needed to be with regards to its use. Obviously I don’t want this to be manual, so when I created TextObject (the text equivalent of AnimationObject) I handled the deletion of text objects in code.
It turned out getting text on screen was mostly straightforward. The only problem was the difference between relative and absolute positioning of text. Obviously I would want the option of having both, but I haven’t come up with a good solution yet. For now I’ve created two objects: TextObject and TextGameObject with game objects being camera-relative while TextObject has an absolute position. When I get to working on the HUD, I might encounter this problem with AnimationObject, so there’s a refactor issue.
In the absence of another prototype idea, I refactored the game itself with an algorithm to brute-force a solution. Taking a purely random approach to the game meant that occasionally really easy puzzles would be thrown up (I coded to stop 0-step puzzles). So I wrote an algorithm that would brute-force a solution - to work out just what are the moves needed to solve the puzzle from any given position. This didn't advance the engine in any way, but was a good coding exercise nonetheless.
Friday, 31 October 2014
Phase 3a: Snake Enhanced
The last couple of weeks has seen a continuation of the approach I took developing Snake. Since there is still more to be done getting the Engine to a functional state, enhancing the existing game seemed like the quickest way of those enhancements in.
The two major enhancements I had for the system were to get animation working, and to get level as its own concept. For the first cut of snake, these were two areas where there was a lot of manual code.
The need for an AnimationObject arose out of the unsuitability of RenderObject and TextureObject to be complete for use as the game object. Each game object was loading its correct texture, then using that to populate the RenderObject associated with rendering. That was fine except for the snake itself, which changed whether the body part was a head, body part, or tail. So the snake had to keep track of both the texture and the render object so it could manually shift the frame corresponding to the right body part.
AnimationObject was my solution. By taking the texture, there was no need for the game object to have continual reference to the texture object (or even retrieve it) in order to change frames. Any animation in the original version was simply the illusion of movement. With AnimationObject, I’d have actual animation at the speed I desired simply by creating the object. It also meant that if the object moved, I could update the game coordinates without having to write the code to manually update the destination rect on the RenderObject.
Instead of trying to put absolutely every scenario into the single AnimationObject, I instead made use of inheritance and polymorphism to get specific functions. I made a RunOnceAnimationObject and a LoopAnimationObject – both of which override the render() method to allow for timer-based animation. The base AnimationObject would be for pointing to a single frame of a texture, while RunOnce would go from start to finish and hold on the final frame, and Loop would loop indefinitely.
The satisfying thing about the AnimationObject classes was that it took no more than an evening to write the code and refactor the game code. The whole process was seamless, and worked with very little effort. Building the level code was more effort, and one of those points where I had to remind myself to design for the game rather than design for some abstract ideal of what I wanted to achieve. The problem is this: Level ideally loads from an XML file (in my case, I wanted those XML files generated by Tiled!), and what is in the XML file on any given tile conforms to a game object.
To solve this problem, I implemented the abstract factory pattern. Level takes a TileFactory (an abstract type) that has a generateTile(int id) method which returns a Tile pointer (also an abstract). Level populates a Vector, where tiles can be retrieved with an x and y coordinate. So what kinds of tiles are produced depends on the concrete TileFactory, and all the SnakeGameObjects that could be Tile had to do was inherit from Tile.
This approach does have a limitation, using Level like this means accessing any Tile will only have the methods that exist on the Tile contract. For now, I put the method bool isCollision() onto Tile to allow for collision detection within the game object. In the future, enhancing Tile to cater for all iterations of what Level could do might prove to be unwieldy. For now, the class does enough to work.
Here’s the enhanced game.
It might not look like much, but there are those enhancements that went on in the backing code – animation was handled automatically, and the world itself was controlled by an XML generated by the Tiled! application. In the spirit of prototype-driven design, I feel I was able to accomplish a number of vital tasks in a short period of time. Of course, there is still more to go, but that requires a different kind of prototype.
The two major enhancements I had for the system were to get animation working, and to get level as its own concept. For the first cut of snake, these were two areas where there was a lot of manual code.
The need for an AnimationObject arose out of the unsuitability of RenderObject and TextureObject to be complete for use as the game object. Each game object was loading its correct texture, then using that to populate the RenderObject associated with rendering. That was fine except for the snake itself, which changed whether the body part was a head, body part, or tail. So the snake had to keep track of both the texture and the render object so it could manually shift the frame corresponding to the right body part.
AnimationObject was my solution. By taking the texture, there was no need for the game object to have continual reference to the texture object (or even retrieve it) in order to change frames. Any animation in the original version was simply the illusion of movement. With AnimationObject, I’d have actual animation at the speed I desired simply by creating the object. It also meant that if the object moved, I could update the game coordinates without having to write the code to manually update the destination rect on the RenderObject.
Instead of trying to put absolutely every scenario into the single AnimationObject, I instead made use of inheritance and polymorphism to get specific functions. I made a RunOnceAnimationObject and a LoopAnimationObject – both of which override the render() method to allow for timer-based animation. The base AnimationObject would be for pointing to a single frame of a texture, while RunOnce would go from start to finish and hold on the final frame, and Loop would loop indefinitely.
The satisfying thing about the AnimationObject classes was that it took no more than an evening to write the code and refactor the game code. The whole process was seamless, and worked with very little effort. Building the level code was more effort, and one of those points where I had to remind myself to design for the game rather than design for some abstract ideal of what I wanted to achieve. The problem is this: Level ideally loads from an XML file (in my case, I wanted those XML files generated by Tiled!), and what is in the XML file on any given tile conforms to a game object.
To solve this problem, I implemented the abstract factory pattern. Level takes a TileFactory (an abstract type) that has a generateTile(int id) method which returns a Tile pointer (also an abstract). Level populates a Vector
Here’s the enhanced game.
It might not look like much, but there are those enhancements that went on in the backing code – animation was handled automatically, and the world itself was controlled by an XML generated by the Tiled! application. In the spirit of prototype-driven design, I feel I was able to accomplish a number of vital tasks in a short period of time. Of course, there is still more to go, but that requires a different kind of prototype.
Saturday, 25 October 2014
Jonathan Blow on Programming Practices
Since the game programming is a hobby of mine – something I do in my spare time – I tend to have a lot more time to think about what I do than to actually do it. I have filled many pages of notebooks and have made many documents with notes ranging from design material, to specific solutions, and everything in between.
So it’s with that in mind that the following video from the Braid developer Jonathan Blow intrigued me, for it advocates effectively the opposite approach to what I've been taking.
One immediate thing that occurs to me is that I’m no Jonathan Blow. Just being able to sit down and write without inhibitions, I'm fairly certain, would get me a mess that doesn't really do much of anything.
The second thing that occurs to me is that it's taken me a year to get half an engine. So the approach I'm taking now is realistically-speaking unsustainable – at least for the goal I'm trying to work towards.
My hope by this stage of my career is that I've absorbed enough of the good design patterns such that the hard work is done for me. What I seemed to have absorbed, however, is knowledge of the existence of patterns minus the knowledge of their application on low-level functions. Since I've had no professional game development experience, this should come as no surprise – why would I have needed to understand patterns outside of their application in Java EE?
Same goes for my stagnated C++ skills, whereby I'm digging through Scott Meyer’s Effective C++ in the hope I can mitigate a lot of the 'gotchas' on areas where Java manages it for you (such as dealing with pointers). My intuitive grasp of class design and function design is rooted in a Java mindset, and C++ is just far enough away from it that my coding style has to be more deliberate. The lack of private functions, especially, is testing my coding sensibilities.
Blow's list of do’s and don'ts seems on the face of it a good one, and especially pertinent if I replace his use of optimisation with "open design" to reflect the kind of design considerations I'm currently working with. I've spent so much time trying to get things just right – of trying to come up with a perfect class order that will enable extensible code. It’s great when it works, but the cost in time and effort has been considerable for that. As Blow pointed out, this kind of approach won’t pay off in the long term.
The other stand-out idea in his talk was the idea of writing specific code over general code. I know I'm especially guilty of doing this. Some of the time there is good reason to write general code, and to my mind it’s especially important to get it right in the core. But it’s something to reflect on that there is good that is fit for purposes without being so flexible it fits every purpose I desire. My Input class comes to mind, and part of that was I think a rationalisation of adding an abstraction atop of SDL's abstraction of the interface. I got what I wanted, but it’s easy to forget the cost of that.
One final lesson that was worth highlighting was the idea of writing code in a single block. This goes dead against the coding principles outline in Robert C. Martin’s Clean Code. In one sense, I can understand this in C++ because of how annoying it is to write function headers for private functions. But Blow’s suggestion about encapsulation is a point well made.
So it’s with that in mind that the following video from the Braid developer Jonathan Blow intrigued me, for it advocates effectively the opposite approach to what I've been taking.
One immediate thing that occurs to me is that I’m no Jonathan Blow. Just being able to sit down and write without inhibitions, I'm fairly certain, would get me a mess that doesn't really do much of anything.
The second thing that occurs to me is that it's taken me a year to get half an engine. So the approach I'm taking now is realistically-speaking unsustainable – at least for the goal I'm trying to work towards.
My hope by this stage of my career is that I've absorbed enough of the good design patterns such that the hard work is done for me. What I seemed to have absorbed, however, is knowledge of the existence of patterns minus the knowledge of their application on low-level functions. Since I've had no professional game development experience, this should come as no surprise – why would I have needed to understand patterns outside of their application in Java EE?
Same goes for my stagnated C++ skills, whereby I'm digging through Scott Meyer’s Effective C++ in the hope I can mitigate a lot of the 'gotchas' on areas where Java manages it for you (such as dealing with pointers). My intuitive grasp of class design and function design is rooted in a Java mindset, and C++ is just far enough away from it that my coding style has to be more deliberate. The lack of private functions, especially, is testing my coding sensibilities.
Blow's list of do’s and don'ts seems on the face of it a good one, and especially pertinent if I replace his use of optimisation with "open design" to reflect the kind of design considerations I'm currently working with. I've spent so much time trying to get things just right – of trying to come up with a perfect class order that will enable extensible code. It’s great when it works, but the cost in time and effort has been considerable for that. As Blow pointed out, this kind of approach won’t pay off in the long term.
The other stand-out idea in his talk was the idea of writing specific code over general code. I know I'm especially guilty of doing this. Some of the time there is good reason to write general code, and to my mind it’s especially important to get it right in the core. But it’s something to reflect on that there is good that is fit for purposes without being so flexible it fits every purpose I desire. My Input class comes to mind, and part of that was I think a rationalisation of adding an abstraction atop of SDL's abstraction of the interface. I got what I wanted, but it’s easy to forget the cost of that.
One final lesson that was worth highlighting was the idea of writing code in a single block. This goes dead against the coding principles outline in Robert C. Martin’s Clean Code. In one sense, I can understand this in C++ because of how annoying it is to write function headers for private functions. But Blow’s suggestion about encapsulation is a point well made.
Friday, 24 October 2014
Prototype-Driven Design
This is designed to be a normative approach based off the three [1, 2, 3] development approaches I wrote about earlier. Namely, how to take the use cases of a simple game to develop and refactor an extensible and versatile underlying code. This is a note to myself for next time.
Bootstrapping the framework
A game is a loop, and the loop has an exit condition. Hitting the exit condition exits the game. To be interesting, while the game is looping, the game has to do stuff. All that should be met with “duh”. What this means is that we have to organise an order of things to do in the loop. You need to create a window, load images, display, capture input, change game code, etc. Organising this basic pattern needs to come first..
The first thing is to get the libraries loading successfully. This may take more time than the task sounds like it would, and doing something slightly unusual (for example, choosing to develop on Windows using MinGW) might not have a single point of clear instructions. Don’t fret if this takes longer, it’s important to get this right.
There are a number of discrete systems that in concert make up a game. Many of these are “core”, and will be used every time in very nearly the same way. As such, each of these systems can be given a basic function (such as render updating the screen each frame), and each function placed as part of a list of functions that are always called. In mine, I called this the Engine façade, where the update() loop took care of everything the engine needed to do with a single call from the game loop.
At this stage, it’s okay to use scenario-based development. “A screen should appear on start-up”, “a button press should quit the game”, etc. Indeed, there’s little more one can do at this stage. The important point is not to overdo this, however, because you a) cannot account for every scenario, and b) what you think will be right scenarios may not be the case. Overdo it at this stage, and prepare to refactor.
The prototype approach
Take a simple game like Snake. It’s a fairly simple game so it won’t take much to work out how to translate what happens on screen into code. It’s also a fairly-well defined game, so there’s not a lot of effort in setting the win / loss conditions and how that translates to a loop. It also tests out what you need in a game – to capture input, to update the game world accordingly, to trigger off sounds, play music, and to update the screen.
The general approach goes like this.
Such a system will also feed back into itself, where later development will override earlier development. The important point is not to get hung up on a decision made earlier if a better decision comes along, after a short while you should have a working game and hence a platform to immediately test out how well the system works.
Like the bootstrap framework, this might take some time to set up. There’s a lot to do going from nothing at all to even a simple working game (without taking every possible shortcut). But what it allows for is very quick refactoring and enhancement. Once you have a fully functioning product, it should be a matter of hours or even minutes to enhance it for the better.
The development phase is similar to Test-Driven Design, though in this case a piece of game functionality is the unit test. You write game code to do something, but it won’t work until you then write the engine enhancement that will make it work.
The allure of design
The prototype approach requires a continual awareness of the allure of design. When making a component, it’s easy to come up with potential uses for that component – all of which takes time to design, develop, and debug. Furthermore, enhancing the system in such a way doesn't mean the work will actually achieve anything. The prototype-driven design in this sense is a way of keeping the developer honest and focused, and not wasting time on the mere potentiality of a function.
This is not a call, however, for the abandonment of design. It’s a call to prevent overdesign, to limit areas where splurges in design can lose sight of the bigger picture. The idea of a chaotic mess of code is what you end up with even with the best of intentions, so there’s no need to add to it if it can be avoided. What I am talking about here is a different kind of chaotic mess – a bloat of code of which only some applies to the end result.
The allure of design is part of the creativity that enables development in the first place, and to some extent it’s necessary for consideration for any potential solution. Otherwise we hit the other extreme – a constant rewriting of the same basic code whenever a new requirement exists. It’s a balancing act, yes, and how the prototype-driven design approach works should be to limit the potential for overdesign.
I suppose the difference I'm trying to articulate is the difference between extensible and bulletproof.
Scope-creep is a good indication that you are moving away from the PD-D and being drawn back into the allure of design. If a problem is getting unwieldy, it’s worth reminding yourself of what the component was meant to achieve in the first place. If it wasn't something with a game-related end product, then that should be a strong indication of overdesign and grounds to stop.
A guideline
The approach sketch above isn't much of a methodology, but a guideline to stay focused. It’s a way to catch that intuitive aesthetic about how code ought to be done and give it a focal point. Furthermore, it’s a guideline that as far as I can tell applies to one person: me. Or to put it another way, this is a sketch of an approach that keeps my distracted-self focused on why I'm doing this in the first place. The desire to “get it right” is coming at the expense of “getting it done”, and this approach seems promising as a way of somewhat alleviating that.
Bootstrapping the framework
A game is a loop, and the loop has an exit condition. Hitting the exit condition exits the game. To be interesting, while the game is looping, the game has to do stuff. All that should be met with “duh”. What this means is that we have to organise an order of things to do in the loop. You need to create a window, load images, display, capture input, change game code, etc. Organising this basic pattern needs to come first..
The first thing is to get the libraries loading successfully. This may take more time than the task sounds like it would, and doing something slightly unusual (for example, choosing to develop on Windows using MinGW) might not have a single point of clear instructions. Don’t fret if this takes longer, it’s important to get this right.
There are a number of discrete systems that in concert make up a game. Many of these are “core”, and will be used every time in very nearly the same way. As such, each of these systems can be given a basic function (such as render updating the screen each frame), and each function placed as part of a list of functions that are always called. In mine, I called this the Engine façade, where the update() loop took care of everything the engine needed to do with a single call from the game loop.
At this stage, it’s okay to use scenario-based development. “A screen should appear on start-up”, “a button press should quit the game”, etc. Indeed, there’s little more one can do at this stage. The important point is not to overdo this, however, because you a) cannot account for every scenario, and b) what you think will be right scenarios may not be the case. Overdo it at this stage, and prepare to refactor.
The prototype approach
Take a simple game like Snake. It’s a fairly simple game so it won’t take much to work out how to translate what happens on screen into code. It’s also a fairly-well defined game, so there’s not a lot of effort in setting the win / loss conditions and how that translates to a loop. It also tests out what you need in a game – to capture input, to update the game world accordingly, to trigger off sounds, play music, and to update the screen.
The general approach goes like this.
- Try to build the game artefact to do what you want it to do.
- If the engine can’t support the functionality, add the functionality.
- If the engine only partially supports the functionality, enhance what’s there.
- If the engine encourages a lot of writing the same code multiple times, refactor.
Such a system will also feed back into itself, where later development will override earlier development. The important point is not to get hung up on a decision made earlier if a better decision comes along, after a short while you should have a working game and hence a platform to immediately test out how well the system works.
Like the bootstrap framework, this might take some time to set up. There’s a lot to do going from nothing at all to even a simple working game (without taking every possible shortcut). But what it allows for is very quick refactoring and enhancement. Once you have a fully functioning product, it should be a matter of hours or even minutes to enhance it for the better.
The development phase is similar to Test-Driven Design, though in this case a piece of game functionality is the unit test. You write game code to do something, but it won’t work until you then write the engine enhancement that will make it work.
The allure of design
The prototype approach requires a continual awareness of the allure of design. When making a component, it’s easy to come up with potential uses for that component – all of which takes time to design, develop, and debug. Furthermore, enhancing the system in such a way doesn't mean the work will actually achieve anything. The prototype-driven design in this sense is a way of keeping the developer honest and focused, and not wasting time on the mere potentiality of a function.
This is not a call, however, for the abandonment of design. It’s a call to prevent overdesign, to limit areas where splurges in design can lose sight of the bigger picture. The idea of a chaotic mess of code is what you end up with even with the best of intentions, so there’s no need to add to it if it can be avoided. What I am talking about here is a different kind of chaotic mess – a bloat of code of which only some applies to the end result.
The allure of design is part of the creativity that enables development in the first place, and to some extent it’s necessary for consideration for any potential solution. Otherwise we hit the other extreme – a constant rewriting of the same basic code whenever a new requirement exists. It’s a balancing act, yes, and how the prototype-driven design approach works should be to limit the potential for overdesign.
I suppose the difference I'm trying to articulate is the difference between extensible and bulletproof.
Scope-creep is a good indication that you are moving away from the PD-D and being drawn back into the allure of design. If a problem is getting unwieldy, it’s worth reminding yourself of what the component was meant to achieve in the first place. If it wasn't something with a game-related end product, then that should be a strong indication of overdesign and grounds to stop.
A guideline
The approach sketch above isn't much of a methodology, but a guideline to stay focused. It’s a way to catch that intuitive aesthetic about how code ought to be done and give it a focal point. Furthermore, it’s a guideline that as far as I can tell applies to one person: me. Or to put it another way, this is a sketch of an approach that keeps my distracted-self focused on why I'm doing this in the first place. The desire to “get it right” is coming at the expense of “getting it done”, and this approach seems promising as a way of somewhat alleviating that.
Thursday, 23 October 2014
Toward a 2D Game Engine: Reflections
Two things that have become really obvious through this process are that a) my C++ skills are really rusty, and b) my expectations are grossly unrealistic. The idea of how long something should take should be calculated only by my present abilities, not by ideal circumstances if only I were in possession of all the relevant knowledge and an industrious disposition.
This is not the first time I've tried doing this, and even back as far as university I tried and failed to do similar. I've read a lot of books and articles trying to find the right answers (or meta-answers) to the questions I've had, but I've failed to be satisfied by what is written. Though well-meaning, the tutorials are especially bad precisely because they break basic design principles for the sake of illustrating a point. The closest to what I wanted was the book Game Architecture and Design (Dave Morris and Andrew Rollings), which had a chapter on engine design. But, again, it’s a sketch of the problem – a 9000ft overview that has to somehow be distilled into discrete complementary units.
That, to me, is where the difficulty lies. It presses the question of why I should bother to begin with. After all, there are plenty of other people much smarter and more educated than I who have put the tools out there to take care of it all for me. To name two examples, there’s RPG Maker, as well as GameMaker Studio, which have a track record. But the trade-off is whether to spend the time learning how to use those tools over designing a system I know how to use. If I were more creative, perhaps those options would be better. But since I'm not overflowing with game ideas (I have 2.5 ideas that could be prototyped at this stage), building the engine itself is what I would consider an endpoint.
What I will consider the end of phase 3 – and I'm hoping this phase will be a completion of code rather than a period of enthusiasm – will be to get a few more core engine features developed such as getting in-game text, the level/tile/camera system, and menus. This seems weeks away, where I understand weeks away in a more realistic rather than pessimistic outlook. Perhaps if I were more competent, I could say a matter of days. But it is a hobby, and a hobby has to work around the rest of life.
One concern, always, is the availability heuristic. That is memories of what I've done previously are going to be tainted by the most pressing issues that came to mind – which in my case is the failure to make headway. One hope in writing all this out is that next time I go through this; I have a record highlighting what I think worked and what didn't. Writing it out gives me a meta-plan for the future, with processes and structures of what I ought (and ought not) to do.
I think this time, though time will tell, I have reusable code. The extra time I spent trying to get the design right may have been a headache (and a significant de-motivator), but I haven’t taken the shortcuts that evidently and inevitably crept through my old code. There was nothing in the rendering class, for example, that was coupled to anything in Snake. Snake depended on the Engine objects, but the engine objects were not constrained that way. If nothing else, I can take that away as a victory of good design.
The graphics that were loaded came from an XML configuration, just as sound and music did. The Engine was flexible enough for the game objects to be used by ID, and that would apply just as well in Snake as in any other game. Even to make an animated food object in snake required little more than updating the PNG, the XML, and what type of object it was. The engine objects took care of the rest. And, at least by my reckoning, that’s the way it should be. To embellish or replace the graphics wouldn't even need a recompilation!
At the end of it all, I don’t know if I have better design principles than I did going in. I'm not even sure if what I did was right (though I'm very much of the opinion that what works is right), but from my perspective I don’t care. I'm not teaching anyone else. I'm not writing a textbook or a manual. This is to achieve what I set out to do, and I'm getting damn close to that goal!
This is not the first time I've tried doing this, and even back as far as university I tried and failed to do similar. I've read a lot of books and articles trying to find the right answers (or meta-answers) to the questions I've had, but I've failed to be satisfied by what is written. Though well-meaning, the tutorials are especially bad precisely because they break basic design principles for the sake of illustrating a point. The closest to what I wanted was the book Game Architecture and Design (Dave Morris and Andrew Rollings), which had a chapter on engine design. But, again, it’s a sketch of the problem – a 9000ft overview that has to somehow be distilled into discrete complementary units.
That, to me, is where the difficulty lies. It presses the question of why I should bother to begin with. After all, there are plenty of other people much smarter and more educated than I who have put the tools out there to take care of it all for me. To name two examples, there’s RPG Maker, as well as GameMaker Studio, which have a track record. But the trade-off is whether to spend the time learning how to use those tools over designing a system I know how to use. If I were more creative, perhaps those options would be better. But since I'm not overflowing with game ideas (I have 2.5 ideas that could be prototyped at this stage), building the engine itself is what I would consider an endpoint.
What I will consider the end of phase 3 – and I'm hoping this phase will be a completion of code rather than a period of enthusiasm – will be to get a few more core engine features developed such as getting in-game text, the level/tile/camera system, and menus. This seems weeks away, where I understand weeks away in a more realistic rather than pessimistic outlook. Perhaps if I were more competent, I could say a matter of days. But it is a hobby, and a hobby has to work around the rest of life.
One concern, always, is the availability heuristic. That is memories of what I've done previously are going to be tainted by the most pressing issues that came to mind – which in my case is the failure to make headway. One hope in writing all this out is that next time I go through this; I have a record highlighting what I think worked and what didn't. Writing it out gives me a meta-plan for the future, with processes and structures of what I ought (and ought not) to do.
I think this time, though time will tell, I have reusable code. The extra time I spent trying to get the design right may have been a headache (and a significant de-motivator), but I haven’t taken the shortcuts that evidently and inevitably crept through my old code. There was nothing in the rendering class, for example, that was coupled to anything in Snake. Snake depended on the Engine objects, but the engine objects were not constrained that way. If nothing else, I can take that away as a victory of good design.
The graphics that were loaded came from an XML configuration, just as sound and music did. The Engine was flexible enough for the game objects to be used by ID, and that would apply just as well in Snake as in any other game. Even to make an animated food object in snake required little more than updating the PNG, the XML, and what type of object it was. The engine objects took care of the rest. And, at least by my reckoning, that’s the way it should be. To embellish or replace the graphics wouldn't even need a recompilation!
At the end of it all, I don’t know if I have better design principles than I did going in. I'm not even sure if what I did was right (though I'm very much of the opinion that what works is right), but from my perspective I don’t care. I'm not teaching anyone else. I'm not writing a textbook or a manual. This is to achieve what I set out to do, and I'm getting damn close to that goal!
Wednesday, 22 October 2014
Phase 3: Snake
Feeling somewhat dejected at my inability to move forward, I decided to give the Engine a test run by making a simple game: Snake. I had a bit of time off work, so I thought it could be something I’d do in a day or two and then build from there. To get it fully working ended up taking much longer, though that was partly because I spent my holidays having an actual break.
What it did teach me, however, was precisely what was easy and what was difficult to do with the Engine as it stood. One development constraint I imposed on myself, which ultimately made it take longer, was I tried to do the Snake game code as wholly separate from the rest of my engine code. So my Play Game State acted as a bridge between the Engine and a separate SnakeGame class that did the equivalent thing – complete with having to mess around with how input is processed.
One thing the process immediately confirmed for me was how inadequate the RenderObject objects were for any sort of game code. In the TextureObject, I had code for pulling out individual frames. In RenderObject, I had code for sorting out source and destination rects for rendering. Between them, both did enough for basic rendering purposes, but it was a pain to do things like change which frame of an animation block to point to. So in order to have my snake change from a head to a body part, and a body part to a tail, was to keep reference to both the snake texture and the render object for the part and do the frame shift in the code.
The reason the objects were the way they were is they served purposes for the function. I wanted an object that could encapsulate an SDL texture while also encapsulating how to break the image down into frames. I achieved what I wanted with the TextureObject, just as I achieved what I wanted with RenderObject, which was an object that could be thrown en masse at the Render class to blindly put onto the screen.
The TextureObject / RenderObject functionality was one of the concerns I had with The Grand Design approach I took earlier. Since SDL does a lot of the core functionality for me, what I'm doing is translating between those core SDL structures and my own Game structures. But because I’m working with the SDL structures as endpoints, I was never sure what value my own wrappers were adding. Furthermore, I was not sure how the wrappers would work in a game. Building Snake gave me a valuable insight into my initial design choices.
It was nice that after I had finally gotten Snake up and working was that I could refactor the code quite quickly. It took me an evening to replace RenderObject with AnimationObject as a game component, with AnimationObject doing what I had to do manually in each game object class when it came to rendering. It took me another evening to expand on AnimationObject so that animation would just work without any intervention on the class. Very quickly I had built up a Run Once and a Loop animation, both of which worked with very little tweaking. Sometimes you've got to love the power of OO!
What was a pleasant surprise was just how much of The Grand Design just worked. Aside from enhancing the RenderObject / Render classes to allow for rotation (so I could point the head in the direction of movement), almost all of the code I did for Snake was in its own set of classes. There was at least some vindication of my earlier approach.
In terms of a development strategy, I find this the most useful process so far. Mainly because now I have a target by which to aim for, and each point of refactoring is an enhancement of the Engine itself. With the AnimationObject, I was able to quickly address the inadequacies of both TextureObject and RenderObject for game code – both were far too low level for any game object to need to have to deal with, and the code general code that would have been useful to ally the two objects was being written multiple times.
I think going forward; this is the way to work. Next I want to get my Level / Camera / Tile combination finished, which I skipped over in Snake by manually generating a list of “Wall” objects that got iterated through every cycle. After that, it’s getting text writing to the screen (an easily achievable enhancement to snake – keeping track of the score and high score), and then I think it'll be enough to start working on a different game prototype to enhance the engine further.
What it did teach me, however, was precisely what was easy and what was difficult to do with the Engine as it stood. One development constraint I imposed on myself, which ultimately made it take longer, was I tried to do the Snake game code as wholly separate from the rest of my engine code. So my Play Game State acted as a bridge between the Engine and a separate SnakeGame class that did the equivalent thing – complete with having to mess around with how input is processed.
One thing the process immediately confirmed for me was how inadequate the RenderObject objects were for any sort of game code. In the TextureObject, I had code for pulling out individual frames. In RenderObject, I had code for sorting out source and destination rects for rendering. Between them, both did enough for basic rendering purposes, but it was a pain to do things like change which frame of an animation block to point to. So in order to have my snake change from a head to a body part, and a body part to a tail, was to keep reference to both the snake texture and the render object for the part and do the frame shift in the code.
The reason the objects were the way they were is they served purposes for the function. I wanted an object that could encapsulate an SDL texture while also encapsulating how to break the image down into frames. I achieved what I wanted with the TextureObject, just as I achieved what I wanted with RenderObject, which was an object that could be thrown en masse at the Render class to blindly put onto the screen.
The TextureObject / RenderObject functionality was one of the concerns I had with The Grand Design approach I took earlier. Since SDL does a lot of the core functionality for me, what I'm doing is translating between those core SDL structures and my own Game structures. But because I’m working with the SDL structures as endpoints, I was never sure what value my own wrappers were adding. Furthermore, I was not sure how the wrappers would work in a game. Building Snake gave me a valuable insight into my initial design choices.
It was nice that after I had finally gotten Snake up and working was that I could refactor the code quite quickly. It took me an evening to replace RenderObject with AnimationObject as a game component, with AnimationObject doing what I had to do manually in each game object class when it came to rendering. It took me another evening to expand on AnimationObject so that animation would just work without any intervention on the class. Very quickly I had built up a Run Once and a Loop animation, both of which worked with very little tweaking. Sometimes you've got to love the power of OO!
What was a pleasant surprise was just how much of The Grand Design just worked. Aside from enhancing the RenderObject / Render classes to allow for rotation (so I could point the head in the direction of movement), almost all of the code I did for Snake was in its own set of classes. There was at least some vindication of my earlier approach.
In terms of a development strategy, I find this the most useful process so far. Mainly because now I have a target by which to aim for, and each point of refactoring is an enhancement of the Engine itself. With the AnimationObject, I was able to quickly address the inadequacies of both TextureObject and RenderObject for game code – both were far too low level for any game object to need to have to deal with, and the code general code that would have been useful to ally the two objects was being written multiple times.
I think going forward; this is the way to work. Next I want to get my Level / Camera / Tile combination finished, which I skipped over in Snake by manually generating a list of “Wall” objects that got iterated through every cycle. After that, it’s getting text writing to the screen (an easily achievable enhancement to snake – keeping track of the score and high score), and then I think it'll be enough to start working on a different game prototype to enhance the engine further.
Tuesday, 21 October 2014
Phase 2: Proof of the Pudding
After a busy phase of work (partly self-inflicted) in the first half of this year, I found myself again ready to get back to the project. I took stock of what I had done and what I still had to go. Then, like last time, I tried knocking off a TODO list.
This time, however, I tried to be a little more advanced in putting new features to the test. To have input fully working meant to be able to catch certain events in a particular way. It meant some substantial refactoring of my Engine façade at times, but I think the end result was worth it. Translating from SDL_Event to my own code may not have added much programmatically, but it was sufficient for what I wanted to do with it.
One thing I found when trying to learn how to use the SDL Input from websites, blogs, and vlogs, was that people would tightly couple the SDL_Input directly with their game. The very trap I was trying to avoid! Even the book I was using did it this way, which meant much of the implementation time was me trying to come up with the right patterns of implementation so that input would work the way I wanted it to.
What I started to do this time was analogous to test-driven development – as analogous as seeing things happen on a screen can be to explicit test cases anyway. I set myself particular outcomes I wanted to see, and used that as the driving point of design. To test my keypress feature, I wanted to be able to pause and resume music. This in turn exposed problems in my Audio class (not to mention what functions I exposed with the Engine façade), as well as problems with my Input class.
These use cases were a direct way of testing and expanding the capabilities of the engine. In the grand scheme of things, it wasn't that much different to what I was doing earlier, but it was more directed this way. For example, I wanted to know how to play around with the alpha channel, so I set the task of gradually fading in the splash screen. To get it working properly required tweaking some fundamental code in the Render class, but I was able to achieve the effect this way.
There comes a limit to this form of development, however. One of the pressing tasks for the engine, and something I’d been putting off until I had more work fleshed out, was the question of how to switch from game coordinates to screen coordinates. The basic logic behind it isn't too complicated, though getting one’s head around it in purely abstract terms was difficult for me.
What was complex about the Camera, though, is that it couldn't happen in isolation. I needed to make a concept of a level, something the Camera would translate from. To have a level meant having a system of Tiles – the fundamental units that made up the level. Tiles themselves needed to have certain properties such as knowing who its neighbours are, or whether the tiles were square or hexagonal. Again, I found myself falling into The Grand Design trap, getting very excited about accounting for the possibilities and trying to get it right the first time. Again, the enthusiasm soon waned.
I found myself a month later trying to take stock of where I was, looking back through my documentation for some hint of what to do next, but I couldn't get the motivation back. Between work and stuff going on at home, I just didn't have the inclination to put in the work to pick up where I left off.
This time, however, I tried to be a little more advanced in putting new features to the test. To have input fully working meant to be able to catch certain events in a particular way. It meant some substantial refactoring of my Engine façade at times, but I think the end result was worth it. Translating from SDL_Event to my own code may not have added much programmatically, but it was sufficient for what I wanted to do with it.
One thing I found when trying to learn how to use the SDL Input from websites, blogs, and vlogs, was that people would tightly couple the SDL_Input directly with their game. The very trap I was trying to avoid! Even the book I was using did it this way, which meant much of the implementation time was me trying to come up with the right patterns of implementation so that input would work the way I wanted it to.
What I started to do this time was analogous to test-driven development – as analogous as seeing things happen on a screen can be to explicit test cases anyway. I set myself particular outcomes I wanted to see, and used that as the driving point of design. To test my keypress feature, I wanted to be able to pause and resume music. This in turn exposed problems in my Audio class (not to mention what functions I exposed with the Engine façade), as well as problems with my Input class.
These use cases were a direct way of testing and expanding the capabilities of the engine. In the grand scheme of things, it wasn't that much different to what I was doing earlier, but it was more directed this way. For example, I wanted to know how to play around with the alpha channel, so I set the task of gradually fading in the splash screen. To get it working properly required tweaking some fundamental code in the Render class, but I was able to achieve the effect this way.
There comes a limit to this form of development, however. One of the pressing tasks for the engine, and something I’d been putting off until I had more work fleshed out, was the question of how to switch from game coordinates to screen coordinates. The basic logic behind it isn't too complicated, though getting one’s head around it in purely abstract terms was difficult for me.
What was complex about the Camera, though, is that it couldn't happen in isolation. I needed to make a concept of a level, something the Camera would translate from. To have a level meant having a system of Tiles – the fundamental units that made up the level. Tiles themselves needed to have certain properties such as knowing who its neighbours are, or whether the tiles were square or hexagonal. Again, I found myself falling into The Grand Design trap, getting very excited about accounting for the possibilities and trying to get it right the first time. Again, the enthusiasm soon waned.
I found myself a month later trying to take stock of where I was, looking back through my documentation for some hint of what to do next, but I couldn't get the motivation back. Between work and stuff going on at home, I just didn't have the inclination to put in the work to pick up where I left off.
Monday, 20 October 2014
Phase 1: The Grand Design
At its core, a game does the same thing. It has to render images, play sounds and music, capture input, and do things with that input. A game loops through those various responsibilities, so the more structured and separated those responsibilities are, then the more flexible this design is.
When looking through my old code, one of the things I noticed was how often I used a quick-fix in the absence of a good design pattern. What this means is ultimately the basic responsibilities like rendering to the screen are tightly coupled with game code. So changing one would mean changing the other. And if I wanted to do a new kind of design, I would have to effectively start from scratch.
It’s with all this in mind that my first attempt was to start with making an extensible and flexible engine, with the engine itself operating separately from the game code.
More specifically, I started with a game idea. I then wrote a very broad outline of an order of development, to first start with getting a working platform to build it on, then gradually building up the game artefacts until I finally had a “complete” project. That way, the list seemed fairly unambitious, just simply a matter of getting the engine working how I wanted it, then it would be a race for the finish.
After a little research, I settled on using SDL, found a textbook and a bunch of resources online, so I was able to start with little things. But at all times, I was conscious of The Grand Design – my conception that it was to be all loosely coupled. The Render class was an endpoint – things were added to RenderLists which the render cycle would systematically draw on a frame-by-frame basis. That, too, would be hidden behind an Engine façade, with the game controller simply telling the Engine where it wanted a RenderObject to go. RenderObject was my own wrapper of the SDL_Texture to take into account Source and Dest SDL_Rects (i.e. what coordinates to take from the original image, and where they would go on the screen), and that was in-turn loaded from TextureObject – my own wrapper for SDL_Texture so frames of a single file could be easily parsed. And so on.
The point isn't to recall everything I did, but to analyse the purpose of it. At each point, I had a rough idea of what I wanted in terms of architecture and function, then I set about building the specifics depending on the task. For example, since I knew that images needed to be loaded, I first wrote a class that’s purpose was to load images based on the directory. Then I expanded that to load from an XML. Then I expanded the XML to contain extra information that would be relevant such as rows and columns so it’s all there in a configuration file.
What I managed to achieve wasn't bad, but there was still a long way to go before it was usable as a game. I had lists of functionality that was built (psychological motivator to show how far I had come), as well as what yet to be built, with my goal being to check those specifics off. But it never really works out like that, and how I imagined progress would go in my planning phase, I continually failed to meet what I thought were modest targets. Weeks of this and my enthusiasm died away.
What I was left with in the end was half-completed. It loaded and rendered images, played sounds and music, took basic input, ran in different game states, yet there was very little to show for it. The sequence went roughly from a blue screen to a change transition from a splash screen to a play state that played a piece of music I wrote and would quit if Q was pressed. Worse still, my TODO list was whittling down, yet I was still a long way off from being able to make something. Eventually, I stopped working on it.
When looking through my old code, one of the things I noticed was how often I used a quick-fix in the absence of a good design pattern. What this means is ultimately the basic responsibilities like rendering to the screen are tightly coupled with game code. So changing one would mean changing the other. And if I wanted to do a new kind of design, I would have to effectively start from scratch.
It’s with all this in mind that my first attempt was to start with making an extensible and flexible engine, with the engine itself operating separately from the game code.
More specifically, I started with a game idea. I then wrote a very broad outline of an order of development, to first start with getting a working platform to build it on, then gradually building up the game artefacts until I finally had a “complete” project. That way, the list seemed fairly unambitious, just simply a matter of getting the engine working how I wanted it, then it would be a race for the finish.
After a little research, I settled on using SDL, found a textbook and a bunch of resources online, so I was able to start with little things. But at all times, I was conscious of The Grand Design – my conception that it was to be all loosely coupled. The Render class was an endpoint – things were added to RenderLists which the render cycle would systematically draw on a frame-by-frame basis. That, too, would be hidden behind an Engine façade, with the game controller simply telling the Engine where it wanted a RenderObject to go. RenderObject was my own wrapper of the SDL_Texture to take into account Source and Dest SDL_Rects (i.e. what coordinates to take from the original image, and where they would go on the screen), and that was in-turn loaded from TextureObject – my own wrapper for SDL_Texture so frames of a single file could be easily parsed. And so on.
The point isn't to recall everything I did, but to analyse the purpose of it. At each point, I had a rough idea of what I wanted in terms of architecture and function, then I set about building the specifics depending on the task. For example, since I knew that images needed to be loaded, I first wrote a class that’s purpose was to load images based on the directory. Then I expanded that to load from an XML. Then I expanded the XML to contain extra information that would be relevant such as rows and columns so it’s all there in a configuration file.
What I managed to achieve wasn't bad, but there was still a long way to go before it was usable as a game. I had lists of functionality that was built (psychological motivator to show how far I had come), as well as what yet to be built, with my goal being to check those specifics off. But it never really works out like that, and how I imagined progress would go in my planning phase, I continually failed to meet what I thought were modest targets. Weeks of this and my enthusiasm died away.
What I was left with in the end was half-completed. It loaded and rendered images, played sounds and music, took basic input, ran in different game states, yet there was very little to show for it. The sequence went roughly from a blue screen to a change transition from a splash screen to a play state that played a piece of music I wrote and would quit if Q was pressed. Worse still, my TODO list was whittling down, yet I was still a long way off from being able to make something. Eventually, I stopped working on it.
Sunday, 19 October 2014
Working Toward a 2D Game Engine
Going back 12 years as an 18 year old faced with a choice of what university course to do, I put down a bunch of courses at my local university, with computer science being the main preference. After my exams were over and I faced the wait to see how I did, I came across a computer science degree at a different university that specialised in game development. I switched preferences, thinking that it was a long shot to begin with. But somehow I did just well enough to make it in, and off I went to do a degree in Game Programming.
Yet when I finished my degree, I didn’t go into the games industry. All the companies I applied for weren't interested, and I was employed to develop Enterprise Java applications – something I've been doing ever since. In a way, from what I hear about the game industry, I don’t consider this a bad thing. But there is a part of me that wishes I was able to do something with that knowledge –at least make something of my own.
It seems every couple of years I have this urge, and I try hard to get something together, only to find I hit a stumbling block, lose interest, and then get on with something else. That cycle of drive, a half-arsed attempt, then ultimately giving up in futility makes me appreciate what people trying to lose weight go through. But clearly it wasn’t working, and like most people trying to lose weight, the exercise achieved little more than highlighting a sense of personal failure.
About a year ago, the urge once again hit me. Over the last 12 months, I’ve had three separate spurts of inspiration, which have had limited success. What I want to write about over the next few posts is what I tried at each point in time, and where I think were the merits and drawbacks of the approach I took.
Phase 1: The Grand Design
Phase 2: Proof of the Pudding
Phase 3: Snake
Reflections
Phase 3a: Snake Enhanced
Phase 3b: Flip Squares
Yet when I finished my degree, I didn’t go into the games industry. All the companies I applied for weren't interested, and I was employed to develop Enterprise Java applications – something I've been doing ever since. In a way, from what I hear about the game industry, I don’t consider this a bad thing. But there is a part of me that wishes I was able to do something with that knowledge –at least make something of my own.
It seems every couple of years I have this urge, and I try hard to get something together, only to find I hit a stumbling block, lose interest, and then get on with something else. That cycle of drive, a half-arsed attempt, then ultimately giving up in futility makes me appreciate what people trying to lose weight go through. But clearly it wasn’t working, and like most people trying to lose weight, the exercise achieved little more than highlighting a sense of personal failure.
About a year ago, the urge once again hit me. Over the last 12 months, I’ve had three separate spurts of inspiration, which have had limited success. What I want to write about over the next few posts is what I tried at each point in time, and where I think were the merits and drawbacks of the approach I took.
Phase 1: The Grand Design
Phase 2: Proof of the Pudding
Phase 3: Snake
Reflections
Phase 3a: Snake Enhanced
Phase 3b: Flip Squares
Tuesday, 21 January 2014
Book Review: Java EE6 Pocket Guide by Arun Gupta

The lack of depth does start to show with the illustrations of examples. They are merely snapshots of the various components in action. Combined with the well-written explanations, this might constitute a sufficient overview for someone trying to make sense of unfamiliar code (we've all been there), but it would be hard to see the practicality of such examples beyond that.
To give an indication of the content, I'll summarise one section where I'm quite familiar with the API (EJB). The Stateful Session Beans, it first gives a brief overview of what they are, then drops into a coding example of how to define them. Then there's another paragraph that goes through the relevant points from the code. After which there's further highlighting of other relevant annotations, then how to access them from the client.
The two areas I could see this book being useful is first for people who are trying to come at a Java EE system without prior familiarity with the language. Java developers making the professional crossover would fit into this category. This could also apply for people familiar with some aspects of the Java EE architecture who are needing to venture into unfamiliar territory. The other area would be as a cheat sheet for Java EE for those not wanting to rely on Google to get specific information on specific components.
This book will not teach you Java EE, but it will help those looking for a nice practical overview of unfamiliar features. And as a reference guide, it might be helpful for quick information about specific features written in an accessible and no-nonsense way.
This book was given freely as part of the O'Reilly Reader Review Program. The book can be purchased here.
Friday, 8 April 2011
The Joy And Sorrow Of Programming
I probably swear more at my work computer than I do anywhere else. Being a professional programmer means I'm in a job where there's certain moments of satisfaction and certain moments of frustration that accompany the skill. When things go right, the job is very rewarding. Puzzle solving is its own reward, so to get paid to do it professionally is about as good as it can get. But of course those moments are tempered with the frustrations that come with not being able to find solutions or having to rework entire conceptual frameworks in order to solve the puzzle. So in that sense it can be a really frustrating and stressful job. Combine that with all the issues that come with development cycles, business requirements, testing, etc. and those moments of satisfaction can at times seem a distant memory.
My extended family often ask me about how I like my job. I say it is what it is, which probably says something about my communication skills more than my work. The truth is that at times I really like being a programmer, and I can't imagine a job I'd rather be doing. Perhaps a few more years of being in the industry will make me so jaded as to question just what I'm still doing, as seems inevitable with most programmers, but for now I still enjoy the job for the merits of the job. It's infuriating, frustrating, intolerable, and at times futile; but has the capacity to provide such satisfaction to keep it a desirable activity.
My extended family often ask me about how I like my job. I say it is what it is, which probably says something about my communication skills more than my work. The truth is that at times I really like being a programmer, and I can't imagine a job I'd rather be doing. Perhaps a few more years of being in the industry will make me so jaded as to question just what I'm still doing, as seems inevitable with most programmers, but for now I still enjoy the job for the merits of the job. It's infuriating, frustrating, intolerable, and at times futile; but has the capacity to provide such satisfaction to keep it a desirable activity.
Wednesday, 2 September 2009
An Ape Sits At A Keyboard...
...and that mostly hairless bipedal ape that we know and love as Richard Dawkins wrote the Weasel program, and put it in his wonderful book The Blind Watchmaker. It's not a simulation of evolution, rather it's showing how adding selection to random events is the opposite of pure chance. Yet creationists don't seem to get this and focus on it like it's anything more than analogy. I wrote a similar program last year, though I "cheated" by locking individual letters when they hit the right character. In the spirit of Creationists not getting it, I've written it again this time without cheating. [source code here]
I'm really surprised that creationists are calling for the source code, it's a very easy program to write. It took me less than an hour writing it in C++. Without "cheating" by locking characters, I was still able to generate a solution. And just to show it wasn't a fluke, I repeated the process hundreds of times changing the mutation rate and number of children; finding a maximum and minimum and an average.
It amazes me that still there are those who go on about the program. It's easy to write and it evidentially works. Anyone who doesn't think that it can or thinks that my code is somehow cheating is welcome to download it and try it out for themselves. Play around with the variables, I made it all parameterised so it is flexible enough to mess around with. How fast it works doesn't really matter, the important thing to take away from the program is that it does work.
I'm really surprised that creationists are calling for the source code, it's a very easy program to write. It took me less than an hour writing it in C++. Without "cheating" by locking characters, I was still able to generate a solution. And just to show it wasn't a fluke, I repeated the process hundreds of times changing the mutation rate and number of children; finding a maximum and minimum and an average.
It amazes me that still there are those who go on about the program. It's easy to write and it evidentially works. Anyone who doesn't think that it can or thinks that my code is somehow cheating is welcome to download it and try it out for themselves. Play around with the variables, I made it all parameterised so it is flexible enough to mess around with. How fast it works doesn't really matter, the important thing to take away from the program is that it does work.
Friday, 5 June 2009
Webcomics For The Programmer
http://slashweb.org/programming/25-best-programmer-webcomic-strips.html
Some of these are just hilarious - at least from a programmer's perspective.
Some of these are just hilarious - at least from a programmer's perspective.
Tuesday, 21 October 2008
There's a monkey sitting at a typewriter
Mathematics is the language of science, so having a grasp on the mathematical concepts used is vital in order to understand much of what is written. Understanding the difference between coincidental and causal events is vital in order to understand statistics. Our brains work on linking causal events, if I press the 'x' key on my keyboard I expect there to be an 'x' written in my text editor. Likewise, all the keys on the keyboard have function and using that same causal relationship I can write entire blog posts. I am conveying information in a causal manner. Now what if it were random? Could a random generator recreate a post of mine, or even a single sentence?
Generating improbability
Now there's a few ways of going about this, take the sentence "mathematics is the language of science", taking the lower-case alphabet and the space character, there are 38 spaces and 27 different characters to go in each. Note that Dawkins did a similar computational experiment in The Blind Watchmaker.
The results
I wrote a java program to simulate these different processes. The source code is available here for anyone wishing to run it themselves. Feel free to modify it, and push it to it's limits. It's very much a cobbled together hack-job, there wasn't much focus on having a clean interface. It's there to show I didn't make the results up, and while the randomness of the PC will mean that the numbers will not turn out the exactly same as mine, they are a good approximation of the procedure.
A run through with a mutation variance of 5
And what of those monkeys?
The first two methods would be simulations of how a monkey would type: the first method would be the equivalent of letting a monkey type the entire post and have it start from scratch over and over if there would be any errors. The 2nd method is like the monkey using the backspace key each time it got something wrong. The evolving algorithm is unlike random chance, it's to illustrate that information of almost infinite improbability can emerge over a far shorter space of time.
Including white space, my posts average around 7,000 characters. By the time a post is finished, the amount of characters I press is probably a lot higher when taking into account typos, spelling and grammatical errors, deletion of poor sentences, and proof reading. All up, it wouldn't be entirely unfair to say I do about 10,000 key strokes per post. Now if I do 200 keystrokes a minute, then it would still take me 50 minutes or so to get the post to where it is now. To evolve or generate something like this by chance is theoretically possible, but practically impossible.
This is why when we see a code or information we know there's intelligence behind it. To look on the great pyramids, the symbols contained therein are the product of intelligence and intent. Anyone who has had previous dealings with the written word would be able to understand the symbols are the same construct. To go back further into human history, the same could be said of cave paintings. It is not the refined symbolism of the written word, but it's evidently communication. Other forms of communication do exist that are not so obvious, smoke signals for example. There are times too when we can mistake natural order and randomness as communication, the stars say astrology is a joke and our futures are not etched into the palms of our hands.
We can infer meaning from non-meaningful processes, this is the problem with the statement "all codes are a product of intelligence". We see patterns all through nature, improbable shapes, repetition, improbable assortment, all of which come from natural processes. One of these patterns is the pattern of DNA, the double-helix structure that has the instructions on the building blocks of life. How could this occur naturally? Well, that's for another entry. The importance of the tests above what to highlight the difference between random chance and a cumulative or an evolutionary process. It was to show that improbable events can be created quite quickly using select processes.
Generating improbability
Now there's a few ways of going about this, take the sentence "mathematics is the language of science", taking the lower-case alphabet and the space character, there are 38 spaces and 27 different characters to go in each. Note that Dawkins did a similar computational experiment in The Blind Watchmaker.
- random chance - suppose you tried to generate every position and every character at once. To get the first character correctly would be a 1 in 27 chance. As would generating the second character. To generate both characters correctly would be (1/27)2 or 1 in 729. To generate three characters correctly would be (1/27)3 or 1 in 19,683. To generate all 38 characters correctly would be 1 in 2738 or 1 in 2.5*1054. So for this one off event to happen, it would take an extraordinary amount of time to generate it by chance with purely random input.
- cumulative chance - instead of trying to generate it all in one go, generating each character individually could work better. Start with the first character, and there's a 1 in 27 chance of generating 'm'. So when 'm' is finally generated, move onto trying to generate the 'a'. Now each subsequent character generation is dependant on earlier chance encounters. To generate 'math' now becomes (1/27) + (1/27) + (1/27) + (1/27), or 1 in 108. For all 38 characters, it's (1/27) * 38 or 1 in 1026. So by progressively doing each step along the way, it takes away an extreme amount of improbability.
- evolving chance - back to generating in one go. By starting at an arbitrary point and tweaking the string, eventually it will come up with the right answer. The mathematics for this is not easily expressed, though it can be expressed in code.
The results
I wrote a java program to simulate these different processes. The source code is available here for anyone wishing to run it themselves. Feel free to modify it, and push it to it's limits. It's very much a cobbled together hack-job, there wasn't much focus on having a clean interface. It's there to show I didn't make the results up, and while the randomness of the PC will mean that the numbers will not turn out the exactly same as mine, they are a good approximation of the procedure.
- random chance will not generate a computational answer, computer randomness is based on seeds so it will run infinitely without ever finding the answer. If it were truly random, then it would still take an almost infinitely long time. I ran the program quite a few times and there wasn't even a fragment of any word that could be considered English.
- cumulative chance has yielded similar results to the mathematical prediction of an average of 1026 iterations. Running it 10 times, I had the following results:
1058, 867, 1077, 1403, 776, 943, 1081, 893, 945, 880.This is an average of 992 iterations for the result. Doing it again for 10 iterations yielded the result 1028. A third time with 100 iterations yielded an average of 1008. A few more times and I did get 1026 as the average over 100 iterations. The practical application of statistics correlated with the theoretical application. - evolutionary chance brought an even quicker result. By adjusting the amount of mutation (a mutation rate of 1 would mean 'd' could only change to either 'e' or 'c', 2 would cover the spread from 'b' to 'f'), the length of time could decrease. The results for running it 100 times on different mutation rates were as follows:


A run through with a mutation variance of 5
Iteration: 1 tptvelwhiqt irsirfpokxpub skrjcgrhcslt
Iteration: 2 - qrtyekzgimy iunhtirkibrubetjuhelueerot
Iteration: 3 - nqt efxfiru irmkojmmkdquddqesjeoxieoov
Iteration: 4 - rmtzedthiov ivmoohqrkdsufencsfhquiesly
Iteration: 5 - whteedtiity iyktnkpulfnudjmcrfgnuiewpz
Iteration: 10 - tftjeclaiww ivdtocswahguajjo fodwieurb
Iteration: 20 - hvtheixaifs in tfwlladguarexffqjpievcr
Iteration: 30 - natheoetias is thyhlamguadeohfinsieucx
Iteration: 40 - mathematigs is th tlacguaoepcflnniescg
Iteration: 50 - mathematics is th uladguauewdformiemce
Iteration: 60 - mathematics is thdilajguabe lfdskiebce
Iteration: 70 - mathematics is thwtlacguaje ofksniefce
Iteration: 80 - mathematics is thkjlauguape of syievce
Iteration: 90 - mathematics is the language of snience
Found iteration 97 - mathematics is the language of scienceAnd what of those monkeys?
The first two methods would be simulations of how a monkey would type: the first method would be the equivalent of letting a monkey type the entire post and have it start from scratch over and over if there would be any errors. The 2nd method is like the monkey using the backspace key each time it got something wrong. The evolving algorithm is unlike random chance, it's to illustrate that information of almost infinite improbability can emerge over a far shorter space of time.
Including white space, my posts average around 7,000 characters. By the time a post is finished, the amount of characters I press is probably a lot higher when taking into account typos, spelling and grammatical errors, deletion of poor sentences, and proof reading. All up, it wouldn't be entirely unfair to say I do about 10,000 key strokes per post. Now if I do 200 keystrokes a minute, then it would still take me 50 minutes or so to get the post to where it is now. To evolve or generate something like this by chance is theoretically possible, but practically impossible.
This is why when we see a code or information we know there's intelligence behind it. To look on the great pyramids, the symbols contained therein are the product of intelligence and intent. Anyone who has had previous dealings with the written word would be able to understand the symbols are the same construct. To go back further into human history, the same could be said of cave paintings. It is not the refined symbolism of the written word, but it's evidently communication. Other forms of communication do exist that are not so obvious, smoke signals for example. There are times too when we can mistake natural order and randomness as communication, the stars say astrology is a joke and our futures are not etched into the palms of our hands.
We can infer meaning from non-meaningful processes, this is the problem with the statement "all codes are a product of intelligence". We see patterns all through nature, improbable shapes, repetition, improbable assortment, all of which come from natural processes. One of these patterns is the pattern of DNA, the double-helix structure that has the instructions on the building blocks of life. How could this occur naturally? Well, that's for another entry. The importance of the tests above what to highlight the difference between random chance and a cumulative or an evolutionary process. It was to show that improbable events can be created quite quickly using select processes.
Subscribe to:
Posts (Atom)